Cet article est à la fois un tutoriel et une démonstration du processus que je suis pour réaliser une « expédition de donnée » seul, où en tant que participant durant un événement de l’École des données. Chaque étape va être détaillée : Trouver, Récupérer, Vérifier, Nettoyer, Explorer, Analyser, Visualiser, Publier.
En fonction de vos données, de votre source ou de vos outils, l’ordre dans lequel vous passerez ces étapes sera différent. Mais le processus est globalement le même.
TROUVER
Une expédition de données peut partir d’une question (i.e. quel est le niveau de pollution de l’air des capitales européennes ?) ou d’un jeu de données que vous voulez explorer. Dans le cas qui nous intéresse, j’avais une question : les marché des magazines de jeux vidéos a-t-il décliné ces dernières années ? Cela fait plusieurs semaine que j’étudie l’industrie du jeu vidéo et c’est une des nombreuses questions auxquelles j’ai cherché des réponses.
Evidemment, il y a d’autres questions intéressantes à explorer, mais il vaut mieux commencer avec une seule question et étendre le champ de recherche par la suite.
Après quelques recherches, la page Wikipedia anglophone s’est avérée être la source la plus complète sur les magazines de jeux vidéos. On y trouve même des informations contextuelles qui seront utiles plus tard (le contexte est essentiel dans l’analyse de données).

https://en.wikipedia.org/wiki/List_of_video_game_magazines
RECUPERER
Les données Wikipedia sont sous forme de tableau. Parfait ! Les scraper est aussi simple que d’utiliser la fonction importHTML dans Google Spreadsheet. Je pourrais copier/coller le tableau, mais ça devient peu pratique lorsque le tableau est très long et le résultat serait mal formatté. LibreOffice et Excel ont des fonctionnalités d’import similaires, bien que moins intuitives.
importHTML requière 3 variables : le lien vers la page, le format des données (tableau ou liste) et le range du tableau (ou de la liste) dans la page. Si aucun rang n’est indiqué, la fonction récupérera le premier tableau qu’elle trouve.
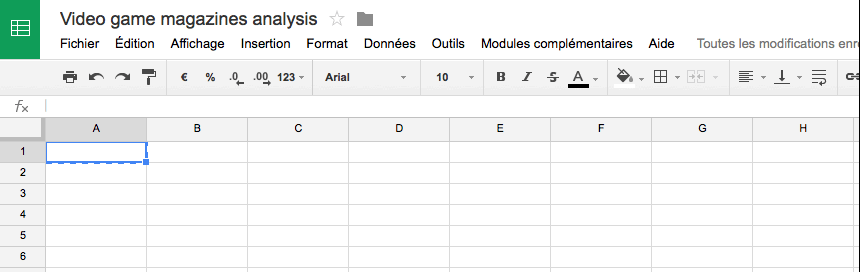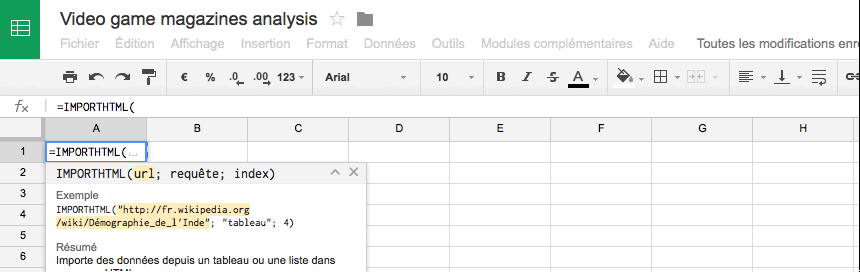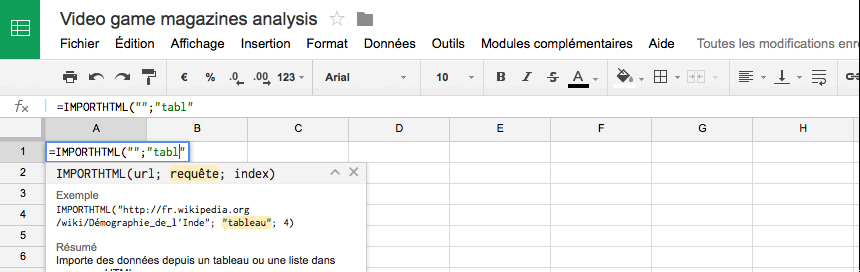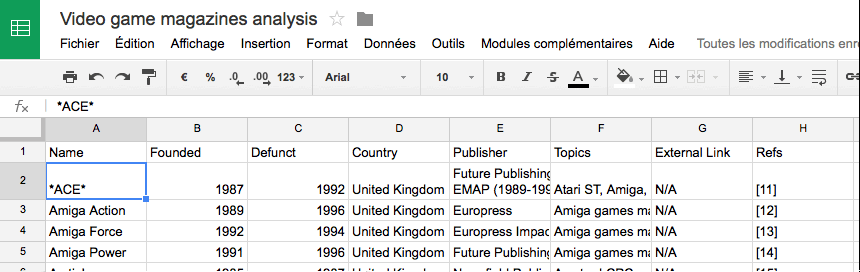
Une fois que j’ai récupéré le tableau, je fais deux choses pour travailler plus rapidement :
- je change la police et la taille des cellules au minimum, pour voir plus d’éléments à la fois,
-
je copie l’ensemble et je fais : Edition->Collage spécial->Coller uniquement les valeurs. De cette façon, le tableau n’est plus lié à importHTML, et je peux le modifier à souhait.
VERIFIER
Ces données vont-elles répondre complèyement à ma question ? J’ai bien les données de base (nom, date de création, date de dépôt de bilan), mais est-ce que tous les magazines y sont ? Une vérification du côté de la page wikipedia francophone sur les magazines de jeux vidéos montre que beaucoup de magazines français manquent à l’appel. La plupart des magazines présents sont des Etats-Unis ou de Grande Bretagne, et sans aucun doute uniquement les plus connus. Je devrai donc prendre cela en compte pour la suite.
NETTOYER
Travailler directement sur vos données brutes n’est jamais une bonne idée. Une bonne habitude est de travailler sur une copie ou de façon non-destructive – ainsi, si vous faites une erreur et que vous n’êtes pas certain de vous, vous pourrez retourner en arrière et comparer votre fichier à l’original.
Puisque je ne veux garder que les magazines de Grande Bretagne et des Etats Unis, je vais :
- Renommer la feuille de calcul originale « Raw Data » (c’est à dire « Données brutes »)
-
Faire une copie de cette feuille et l’appeler « Clean Data » (c’est à dire « Données nettoyées »)
-
Trier par ordre alphabétique la feuille « Clean Data » selon la colonne « Country»
-
Supprimer toutes les lignes correspondant aux pays autres que la Grande Bretagne et les Etats-Unis.

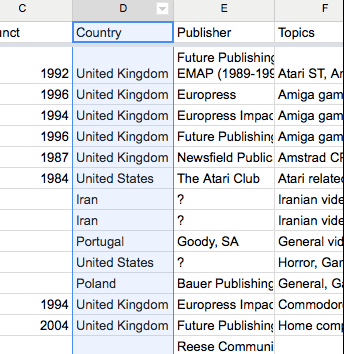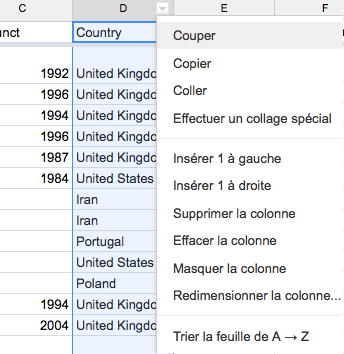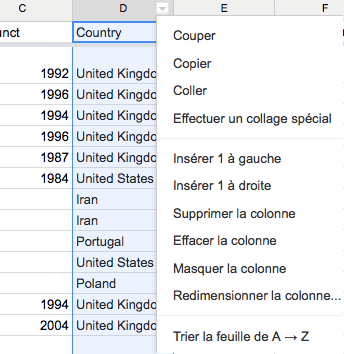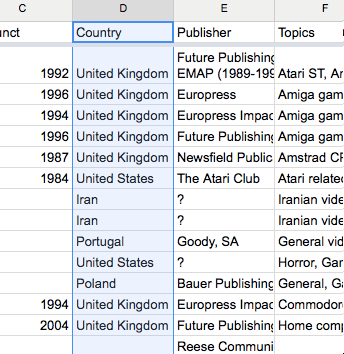
Astuce : pour éviter de faire bouger les en-têtes de colonnes quand vous triez vos données, aller à Affichage->Figer une ligne.
D’autres ajustements mineurs doivent être réalisés, mais ils sont assez légers pour que j’ai pas recours à une outil spécialisé comme Open Refine :
- Scinder les lignes où deux pays sont listés (i.e. PC Gamer devient PC Gamer UK et PC Gamer US)
-
Supprimer la colonne « ref », qui n’ajoute aucune information
-
Supprimer une ligne où la date de création est manquante.
EXPLORER
J’appelle « exploration » l’étape à laquelle je pense aux différentes réponses que mon jeu de données nettoyé peut donner à ma question initiale. Votre narration sera beaucoup plus riche si vous attaquez la question de plusieurs angles.
Il y a plusieurs choses que je pourrais chercher dans les données :
- des particularités intéressantes
-
des changements au cours du temps
-
des expériences personnelles
-
des interactions surprenantes
-
des comparaisons qui permettent de contextualiser
Que puis-je donc faire ? Je peux :
- afficher le nombre de magazines en existence chaque année, ce qui me permettra de savoir si il y a eu un déclin ou non (changements au cours du temps)
-
regarder le nombre de magazines créés par année, pour savoir si le marché est toujours dynamique (changements au cours du temps)
Dans le cadre de ce tutoriel, je vais me concentrer sur la seconde question, c’est à dire le nombre de magazines créés par année. Un autre tutoriel sera dédié à la première, car elle demande une approche plus complexe en raison du format des données.
A ce stade, j’ai plein d’autres idées en tête : Est-ce que je peux déteminer l’année ayant produit le plus de magazines (particularités intéressantes) ? Est-ce que la comparaison avec les données sur les sites de jeu vidéo serait intéressante (comparaisons qui permettent de contextualiser) ? Quels magazines ont la plus grand longévité (particularité intéressante) ? Toutes ces questions valent le coup d’être explorées, mais elle ne le seront pas dans le cadre de ce tutoriel. Il vaut mieux à ce stade les noter afin de les revisiter plus tard : traiter les questions une à une permet d’éviter les erreurs.
ANALYSE
Il s’agit ici d’appliquer les techniques d’analyse de données à mon jeu de données et d’explorer les visualisations possibles.
La façon la plus rapide de répondre à la question « combien de magazines ont été créés chaque année ? » est d’utiliser un tableau croisé dynamique.
- Sélectionnez la portion des données qui répondent à la question (les colonnes « name » et « founded »)
-
Aller à Données -> Tableau croisé dynamique
-
Dans la feuille de calcul créée, sélectionnez le champ « Founded » dans le menu déroulant de Lignes. Les années de création (founded) sont ordonnées et groupées, ce qui nous permet de compter le nombre de magazines pour chaque année, en commençant par la plus éloignée.
-
Je sélectionne ensuite le champ « Name » dans le menu déroulant de Valeurs. Le tableau croisé dynamique s’attend à des nombres par défaut (il essaye de réaliser une addition), donc rien ne s’affiche. Il faut sélectionner COUNTA, qui est la formule qui va compter le nombre d’éléments.

Ces données peuvent être visualisées avec un graphique de en barres.

source: https://en.wikipedia.org/wiki/List_of_video_game_magazines
La ligne de tendance semble indiquer une déclin dans la dynamique du marché, mais il est difficile de déceler la tendance avec les barres seules. Si on groupe les années par demi-décades, la tendance est plus claire :

Notre nouveau graphique en barre ressemble donc à ça :

https://en.wikipedia.org/wiki/List_of_video_game_magazines
Le nombre de magazines créée chaque 5 ans décroit beaucoup dans le années aux alentour de 2000. La baisse dramatique des années 1986-1990 est certainement une conséquence du krash du jeu vidéo de 1983.
Contrairement à ce que l’on aurait pu supposer, le marché est toujours dynamique, avec un magazine créé chaque année les 5 dernières années. L’histoire que l’on va pouvoir raconter n’en sera que plus nuancée et intéressante.
VISUALISER
Dans le cadre de ce tutoriel, les graphiques créées durant l’étape d’analyse suffisent à ma narration. Mais dans l’hypothèse où mes résultats auraient requis une visualisation plus complexe, voire interactive, pour être communiqués, ce travail aurait été traité au sein de l’étape « visualiser ».
PUBLIER
Où et comment publier est une question essentielle que vous devrez vous poser au moins une fois. Peut-être que vous faites partie d’une organisation qui a son site web et la question ne se pose pas. Mais si ce n’est pas le cas, et que vous n’avez pas encore de site web, la réponse peut-être plus longue à trouver. WordPress est un mastodonte qui en fait peut-être trop pour vos besoins. Tumblr est une possibilité, si vous êtes prêt à modifier le code à la main. Pour ceux qui baignent dans le milieu de la programmation, une combinaison de Github Pages et de Jekyll peut-être une bonne idée. Si vous avez besoin d’une base de données légère, jetez un oeil à tabletop.js, qui permet d’utiliser une Google spreadsheet comme une base de donnée basique.
Conclusion
Toute expédition de donnée, quelque soit sa taille ou sa complexité, peut être gérée avec ce processus. En suivant les étapes listées ci-dessus, vous vous évitez de nombreux maux de tête et problèmes potentiels. Bien souvent vous aurez à récupérer et analyser des données supplémentaire pour contextualiser les données initiales, mais il s’agit alors simplement de répéter les différentes étapes autant de fois que nécessaire.
Pour en savoir plus sur l’Ecole des données, vous pouvez consulter la page wiki dédiée
Pour participer au projet, demander l’organisation d’un atelier ou devenir partenaire du projet, contactez nous : [email protected]
![]()

Le samedi 7 mars l’Ecole des données, en partenariat avec Silicon Banlieue, a organisé un nouvel atelier gratuit, cette fois-ci autour des données du cinéma. Après une introduction décrivant les grandes étapes du traitement des données, trois situations ont été abordées : le nettoyage des données textuelles, l’exploration et l’analyse des données, et enfin la visualisation géographique avec des outils gratuits en ligne.

Les grandes étapes d’une expédition de donnée (cliquez pour voir en grand)
1. Les données
Les données utilisées ont été gracieusement fournies par la mission Images et Cinéma du Conseil général du Val d’Oise. Elles consistaient en un fichier de 1174 lignes représentant tous les tournages filmés sur le territoire du Val d’Oise depuis 1901. Elles ont été nettoyées avant l’atelier afin de les rendre plus facilement utilisables.
2. Le nettoyage des données textuelles
Le fichier étant essentiellement composés de texte (titres, noms, commentaires…), c’était l’occasion d’utiliser OpenRefine, un outil gratuit de nettoyage de jeux de données, particulièrement adapté aux données textuelles.
Le logiciel a fait grande impression sur les participants : bien que très puissant, il reste facile à utiliser pour les tâches les plus simples.
A ne pas oublier :
- Sur Mac, le système d’exploitation risque de considérer le fichier d’installation de OpenRefine comme corrompu. Il suffit d’aller de changer temporairement le réglage suivant : Préférences Système -> Sécurité et confidentialité -> Général -> autoriser les applications téléchargées de n’importe où.
- Comme lors de l’ouverture d’un fichier .csv sur Excel/Libre Office, il faut choisir le format UTF-8 sur la page d’accueil d’OpenRefine, à côté de « Character Encoding ».
- Si OpenRefine est ouvert mais qu’aucune fenêtre ne s’ouvre, il suffit d’ouvrir un nouvel onglet du navigateur à l’adresse http://127.0.0.1:3333/
3. L’exploration et l’analyse de données
L’exploration consiste à poser des questions précises et pertinentes auxquelles le jeu de donnée pourrait répondre. Cette étape permet de cadrer la phase d’analyse, qui consiste à utiliser des outils mathématique et statistiques pour extraire des réponses des données. Elle permet aussi de poser la question des données supplémentaires qu’il faudrait récupérer pour mieux contextualiser le jeu de données.
Quelques exemples de questions posées par les participants :
- Combien de différentes nationalités parmi les réalisateurs ?
- Quelle répartition des films dans le temps ?
- Quel genre de film est le plus représenté ?
- Quels sont les lieux les plus attractifs pour les équipes de tournages ?
- Certains des films tournés ont-ils été nominés ou primés aux Oscar ?
Certaines questions ont permis de voir la limite des données : la précision géographique est limitée au niveau ville, et le genre des films n’est pas présent dans le jeu de données.
Cependant les questions comme celles du genre et des Oscar, qui nécessitent la récupération de données additionnelles, sont possibles avec l’utilisation de l’outil RechercheV (Vlookup en anglais) dans Excel ou LibreOffice. Pour détailler l’usage de cette fonction, un tutoriel sera publié sur le site de l’Ecole des données
4. La visualisation
Quelques outils gratuits de visualisation ont été présentés, et en particulier CartoDB, un outil en ligne permettant de faire très rapidement des cartes personnalisables. CartoDB a la possibilité de géocoder les nom de ville ou adresses présentes dans votre fichier, ce qui évite d’avoir à chercher les coordonnées soi-même. D’autres outils comme Umap our Mapbox permettent d’arriver à des résultats similaires.

Carte du nombre de film présents tournés dans le Val d’Oise, par ville. https://clombion.cartodb.com/viz/e1885d00-d3a6-11e4-b5a2-0e018d66dc29/public_map
Pour en savoir plus sur l’Ecole des données, vous pouvez consulter la page wiki dédiée
Pour participer au projet, demander l’organisation d’un atelier ou devenir partenaire du projet, contactez nous : [email protected]
![]()